

Fixing Rails Connection Stickiness to Aurora
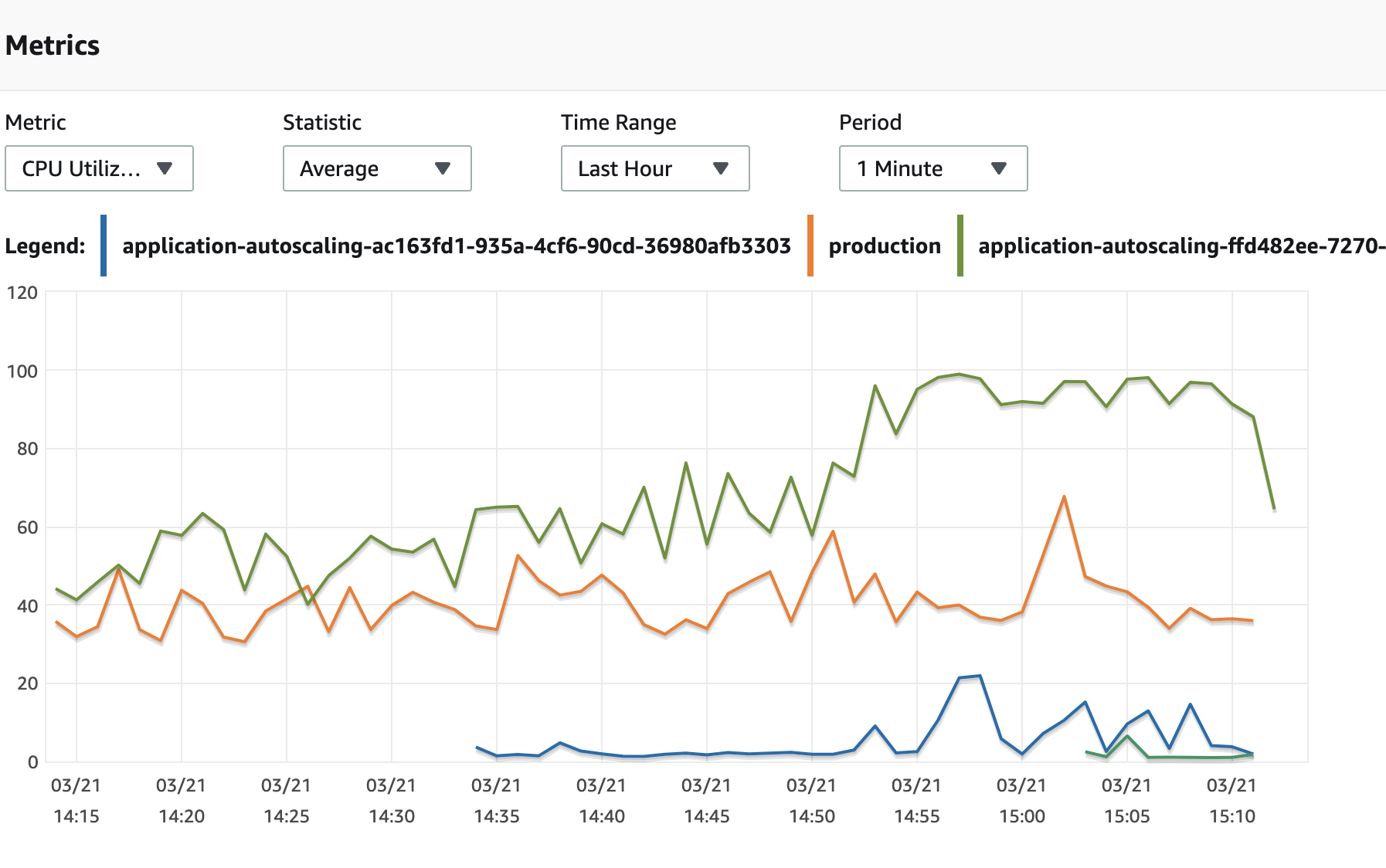
“Why is one of our reader instances taking all the load?” I asked myself one Friday afternoon at work.
The green line represents the current reader CPU usage, while the blue line represents the reader instance that automatically scaled up an hour ago.
Checking Assumptions

My coworker helpfully chimed in with the always useful haiku to help me focus on the important things.
Clearly something is wrong here, I started double checking assumptions.
- AWS Aurora is a managed database, providing us with a PostgreSQL compatible interface.
- AWS Aurora provides auto-scaled reader databases. Scaling up when usage is high and down when usage is low.
- AWS Aurora uses two endpoints, a reader and writer endpoint.
- The reader endpoints use round-robin load balancing via DNS.
- Our production web workers are configured to connect to the reader endpoint for read-only queries.
- Restarting our web workers appears to redistribute load evenly again and we’re able to mitigate the hot-spotting when it comes up.
So why are we seeing stickiness?
When I run netstat -an | grep ':5432' to see open PostgreSQL connections I see about 90% of requests stuck to one of the readers. A handful of our web workers are connected to the other readers. This seems to make sense because sometimes a web worker will timeout and automatically get restarted. This seems to force a fresh connection. We see the same behavior during a deploy or manual restart of our web workers.
We currently monkey-patch the PostgreSQLAdapter#active? method to expire our connections periodically to help with failover events. A naive read of it indicated that it should force a reconnection every few minutes or so and that was indeed working. Further digging discovered that it was resetting the initial PG::Connection object in the connection pool rather than reaping the connection and creating a fresh one. Lastly the PG::Connection#reset method doesn’t force DNS to resolve again. Ooof!
How ActiveRecord Connections Work
On the first ActiveRecord request, something like User.first, a new connection is checked out or created from the connection pool. On checkout the connection is verified. Even in single threaded workloads, like Unicorn, a pool is maintained, although with typically only a single connection.
Below are the relevant code snippets from the Rails 6.1 branch of ActiveRecord.
# Check-out a database connection from the pool, indicating that you want
# to use it. You should call #checkin when you no longer need this.
#
# This is done by either returning and leasing existing connection, or by
# creating a new connection and leasing it.
#
# If all connections are leased and the pool is at capacity (meaning the
# number of currently leased connections is greater than or equal to the
# size limit set), an ActiveRecord::ConnectionTimeoutError exception will be raised.
#
# Returns: an AbstractAdapter object.
#
# Raises:
# - ActiveRecord::ConnectionTimeoutError no connection can be obtained from the pool.
def checkout(checkout_timeout = @checkout_timeout)
checkout_and_verify(acquire_connection(checkout_timeout))
end
# Checks whether the connection to the database is still active (i.e. not stale).
# This is done under the hood by calling #active?. If the connection
# is no longer active, then this method will reconnect to the database.
def verify!
reconnect! unless active?
end
We had monkeypatched active? to expire a connection after a few minutes which only succeeded in resetting the connection instead of performing a true reconnect. The following code in the PostgreSQLAdapter shows why.
# Close then reopen the connection.
def reconnect!
@lock.synchronize do
super
@connection.reset
configure_connection
rescue PG::ConnectionBad
connect
end
end
What Did Work
We used the following monkey-patch to force a true reconnection and force a new DNS resolution to occur. The random interval for expiry prevents multiple reconnects from all occuring at the same time.
module ActiveRecord
module ConnectionAdapters
class PostgreSQLAdapter < AbstractAdapter
def expired?
@expired ||= rand(5.0..10.0).minutes.from_now
@expired < Time.current
end
def active?
return false if expired?
@lock.synchronize do
@connection.query "SELECT 1"
end
true
rescue PG::Error
false
end
def reconnect!
@lock.synchronize do
super
disconnect!
connect
@expired = nil
rescue PG::ConnectionBad
connect
end
end
end
end
end
In the process of fixing this we uncovered that since the connections weren’t being destroyed as expected we were seeing a connection reset on every connection checkout 😅. On resetting @expired after a reconnect! we saw an immediate improvement in median response time from 42ms down to about 17ms. Not enough to be noticeable but every ms counts!
Next Steps
Breaking the above out into a new adapter that inherits from PostgreSQLAdapter might be cleaner than monkey-patching. Perhaps even adding a configuration option and trying to get it merged in as a feature to ActiveRecord. Overall the above was working well for us and we started seeing immediate relief.